phpinfo 与条件竞争
我们对任意一个 PHP 文件发送一个上传的数据包时,不管这个后端是否有处理 $_FILES 的逻
辑,PHP 都会将用户上传的数据先保存到一个临时文件中,这个文件一般位于系统临时目录,
文件名是 php 开头,后面跟 6 个随机字符;在整个 PHP 文件执行完毕后,这些上传的临时文件
就会被清理掉。
我们可以包含这个临时文件,完成 getshell。但这里面暗藏了一个大坑就是,临时文件的文
件名我们是不知道的。所以这个利用的条件就是,需要有一个地方能获取到文件名,例如
phpinfo。phpinfo 页面中会输出这次请求的所有信息,包括 $_FILES 变量的值,其中包含
完整文件名。
但第二个难点就是,即使我们能够在目标网站上找到一个 phpinfo 页面并读取到临时文件名, 这个文件名也是这一次请求里的临时文件,在这次请求结束后这个临时文件就会被删掉,并 不能在后面的文件包含请求中使用。所以此时需要利用到条件竞争(Race Condition),原 理也好理解——我们用两个以上的线程来利用,其中一个发送上传包给 phpinfo 页面,并读取 返回结果,找到临时文件名;第二个线程拿到这个文件名后马上进行包含利用。
这是一个很理想的状态,现实情况下我们需要借助下面这些方法来提高成功率:
- 使用大量线程来进行第二个操作,来让包含操作尽可能早于临时文件被删除
- 如果目标环境开启了 output_buffering 这个配置(在某些环境下是默认的),那么 phpinfo 的页面将会以流式,即 chunked 编码的方式返回。这样,我们可以不必等到 phpinfo 完全显示完成时就能够读取到临时文件名,这样成功率会更高
- 可以在请求头、query string 里插入大量垃圾字符来使 phpinfo 页面更大,返回的时间更 久,这样临时文件保存的时间更长。但这个方法在不开启 output_buffering 时是没有影 响的
利用 pearcmd 从 LFI 到 getshell
https://blog.csdn.net/rfrder/article/details/121042290
简单来说,在安装了 pear (PHP Extension and Application Repository) 的情况下可以利
用 pearcmd.php 从 $_SERVER['argv'] 获取参数的特性来操控 pear 程序,达到下载远程
php 文件的目的
Phar 利用姿势
- 绕过文件上传限制
- 反序列化 meta-data
https://xz.aliyun.com/t/3692 https://paper.seebug.org/680/
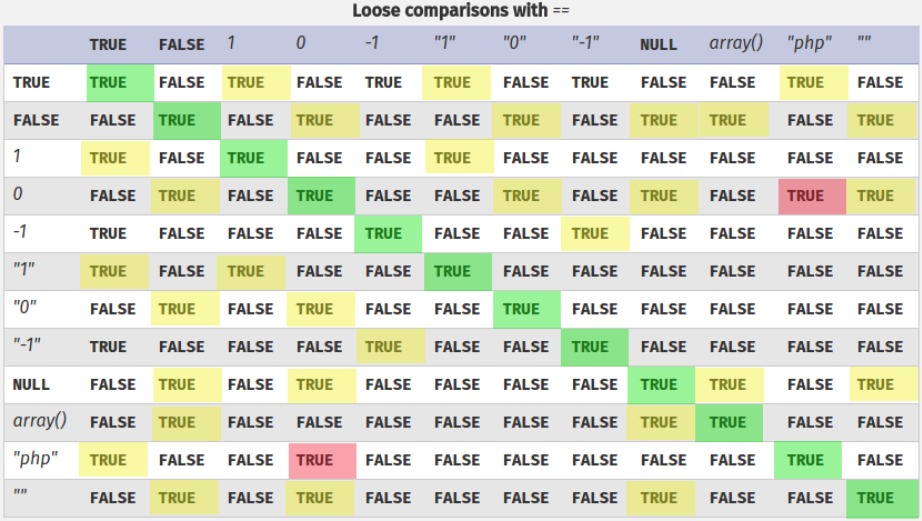
Switch-Case 松散比较
PHP 利用 PCRE 回溯次数限制绕过某些安全限制
正则匹配引擎分为 DFA(确定性有限状态自动机)与 NFA(非确定性有限状态自动机)
- DFA: 从起始状态开始,一个字符一个字符地读取输入串,并根据正则来一步步确定至下 一个转移状态,直到匹配不上或走完整个输入
- NFA:从起始状态开始,一个字符一个字符地读取输入串,并与正则表达式进行匹配,如 果匹配不上,则进行回溯,尝试其他状态
由于 NFA 的执行过程存在回溯,所以其性能会劣于 DFA,但它支持更多功能。大多数程序语言 都使用了 NFA 作为正则引擎,其中也包括 PHP 使用的 PCRE 库
但 PHP 为了防止正则表达式的拒绝服务攻击(reDOS),给 pcre 设定了一个回溯次数上限
pcre.backtrack_limit。我们可以通过 var_dump(ini_get('pcre.backtrack_limit')); 的
方式查看当前环境下的上限,回溯次数上限默认是 100 万,当回溯次数超过上限,
preg_match 函数会返回 False(正常情况返回 1 或 0)
所以,通过发送超长字符串可以绕过一些使用 preg_match 函数实现的安全检测
poc = f"aaa<?php eval($_POST[txt]);//{'a'*1000000}"修复方法
preg_match('/expression/', $data) === 0